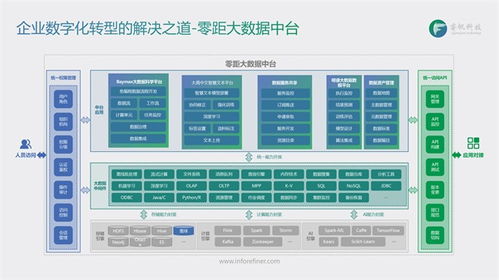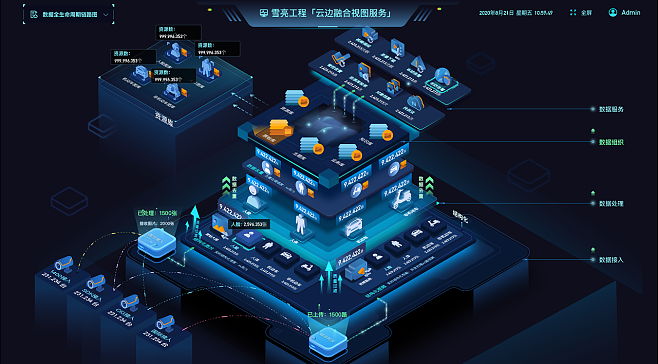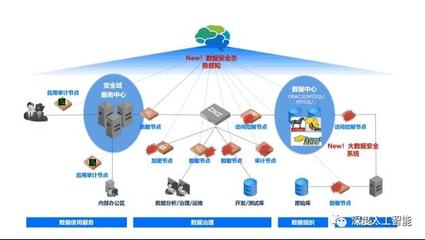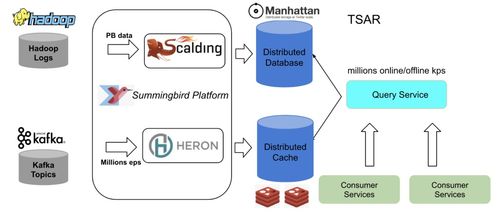
在數據處理服務領域,許多企業正從傳統的Lambda架構和Twitter流處理方案轉向基于Kafka與數據流的新架構。這一轉變不僅提升了數據處理的效率,還帶來了更好的可擴展性和實時性。
為什么需要棄用Lambda架構?Lambda架構雖然將批處理和流處理分開,但帶來了系統復雜性高、維護成本大的問題。企業需要維護兩套代碼邏輯,導致開發周期長且容易出錯。同時,Twitter的流處理解決方案在擴展性和容錯性方面存在限制,難以應對高吞吐量的數據場景。
相比之下,Kafka作為分布式事件流平臺,提供了高吞吐、低延遲的數據處理能力。結合現代數據流架構,如Apache Flink或Kafka Streams,企業可以實現統一的流處理和批處理模式,簡化系統設計。Kafka的持久化存儲和分區機制確保了數據可靠性和水平擴展性,而數據流技術支持復雜事件處理和狀態管理。
新架構的優勢包括:實時數據處理能力增強,支持從數據采集到分析的全流程;降低了運維復雜度,通過單一平臺處理多種數據任務;提高了系統的彈性,能夠快速適應業務變化。企業通過這一轉型,不僅優化了資源利用率,還為AI和實時分析應用奠定了堅實基礎。
從Lambda和Twitter轉向Kafka與數據流新架構是數據處理服務演進的必然趨勢。它助力企業構建更高效、可靠的實時數據處理系統,推動數字化轉型的深入發展。