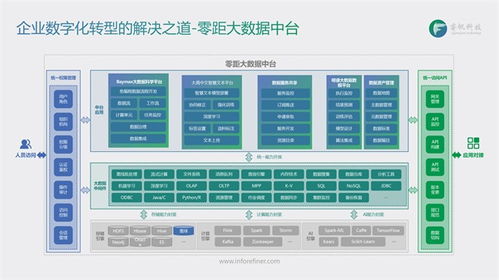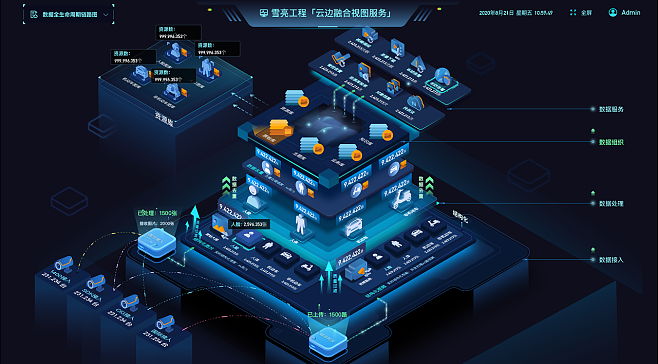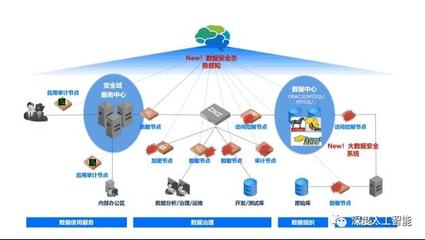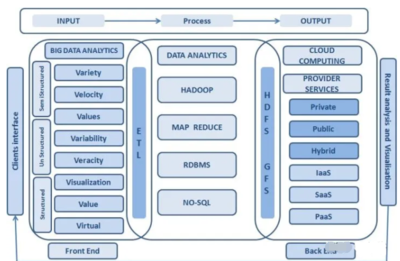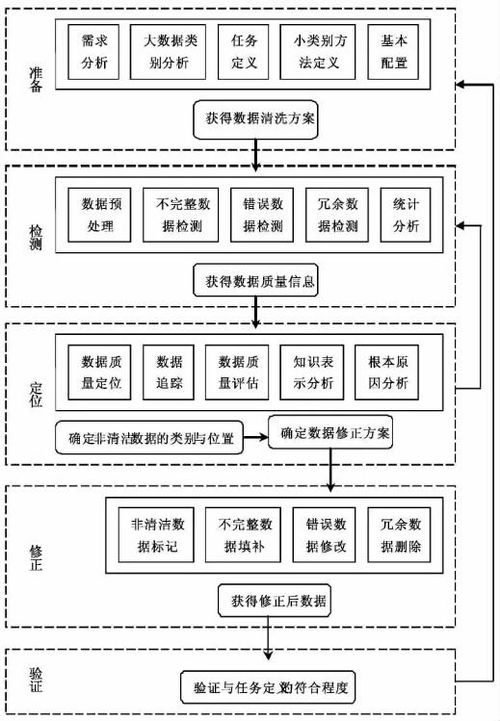
隨著大數(shù)據(jù)技術的快速發(fā)展,數(shù)據(jù)已成為知識服務的重要基礎。原始數(shù)據(jù)往往存在各種質量問題,如不一致、重復、缺失和噪聲等,這些都會影響后續(xù)知識提取和服務的準確性。因此,數(shù)據(jù)清理成為大數(shù)據(jù)處理的關鍵環(huán)節(jié)。本文以面向知識服務為背景,探討大數(shù)據(jù)清理的方法和技術框架。
一、大數(shù)據(jù)清理的核心目標
數(shù)據(jù)清理的主要目標是提升數(shù)據(jù)質量,使其適合知識服務應用。具體包括:
- 一致性:消除數(shù)據(jù)中的邏輯矛盾。
- 完整性:補全缺失值或處理缺失數(shù)據(jù)。
- 準確性:糾正錯誤數(shù)據(jù)和異常值。
- 唯一性:去除重復記錄。
- 時效性:確保數(shù)據(jù)反映最新狀態(tài)。
二、面向知識服務的大數(shù)據(jù)清理技術框架
面向知識服務的大數(shù)據(jù)清理不僅關注基礎數(shù)據(jù)質量,還需考慮知識表達和語義一致性。其技術框架通常包括以下層次:
- 數(shù)據(jù)獲取與預處理層
- 從多源(如數(shù)據(jù)庫、日志、傳感器)采集數(shù)據(jù)。
- 進行格式統(tǒng)一、編碼轉換和初步過濾。
- 數(shù)據(jù)質量評估層
- 定義質量指標(如完整性率、一致性得分)。
- 利用統(tǒng)計分析、規(guī)則引擎評估數(shù)據(jù)問題。
- 核心清理處理層
- 重復數(shù)據(jù)檢測與合并:使用相似度算法(如編輯距離、Jaccard系數(shù))識別重復記錄,并基于業(yè)務規(guī)則合并。
- 缺失值處理:根據(jù)場景選擇刪除、插補(均值、回歸預測)或標記缺失。
- 異常值檢測:通過統(tǒng)計方法(Z-score、IQR)或機器學習模型識別異常。
- 不一致糾正:利用規(guī)則庫或知識圖譜修正語義矛盾(如單位不統(tǒng)一、編碼沖突)。
- 知識語義整合層
- 結合領域知識(如本體、 taxonomy)進行語義清理。
- 實體解析與鏈接,確保數(shù)據(jù)對象在知識服務中具有一致標識。
- 清理驗證與優(yōu)化層
- 通過抽樣驗證、用戶反饋評估清理效果。
- 基于歷史數(shù)據(jù)優(yōu)化清理規(guī)則和參數(shù)。
三、數(shù)據(jù)處理服務在清理中的應用
數(shù)據(jù)處理服務為大數(shù)據(jù)清理提供可擴展、自動化的支持:
- 服務化接口:通過API或工作流引擎,將清理功能封裝為服務,供知識服務系統(tǒng)調用。
- 分布式計算:利用Hadoop、Spark等框架,實現(xiàn)海量數(shù)據(jù)的高效清理。
- 實時處理:結合流處理技術(如Flink),支持對動態(tài)數(shù)據(jù)的即時清理。
- 監(jiān)控與管理:提供服務運行狀態(tài)監(jiān)控、清理日志和性能報告。
四、挑戰(zhàn)與未來方向
盡管技術框架日益成熟,大數(shù)據(jù)清理仍面臨挑戰(zhàn):
- 多源異構數(shù)據(jù)的語義集成。
- 實時清理的延遲與準確性平衡。
- 隱私保護與數(shù)據(jù)安全的兼顧。
未來,隨著人工智能和知識圖譜技術的發(fā)展,數(shù)據(jù)清理將更加智能化、自適應,并能深度融合領域知識,從而更好地服務于知識發(fā)現(xiàn)與決策支持。
面向知識服務的大數(shù)據(jù)清理是一個系統(tǒng)化工程,需要結合數(shù)據(jù)質量理論、計算技術和領域知識。通過構建多層次的技術框架,并依托數(shù)據(jù)處理服務,可以有效提升數(shù)據(jù)價值,為知識服務提供可靠的數(shù)據(jù)基礎。