在數字化轉型的浪潮中,數據中臺已成為企業實現數據驅動的關鍵基礎設施。一個通用的數據中臺架構能夠整合多源數據、提供統一的數據服務,并支持業務快速創新。本文將重點探討數據處理服務在數據中臺中的核心作用,并詳細介紹如何構建一個高效、可擴展的數據處理架構。
一、數據中臺架構概述
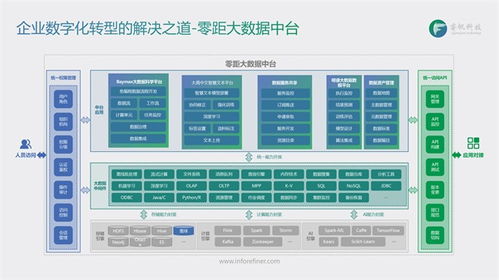
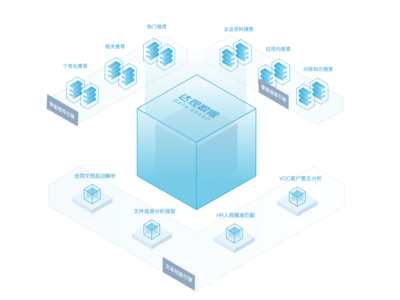
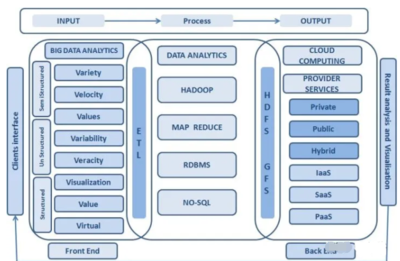
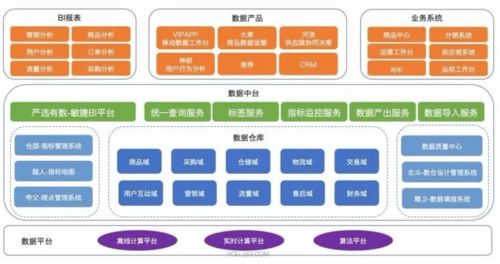
數據中臺架構通常分為數據采集、數據存儲、數據處理、數據服務和數據治理五大層次。數據處理服務作為核心環節,承擔著數據清洗、轉換、集成和計算的任務,確保數據質量與可用性。
二、數據處理服務的關鍵組件
- 數據集成與采集:通過ETL(抽取、轉換、加載)或ELT工具,從業務系統、日志、第三方API等數據源實時或批量采集數據,并存入數據湖或數據倉庫。
- 數據清洗與標準化:利用規則引擎或機器學習模型,處理數據中的噪聲、缺失值和重復項,統一數據格式與標準,確保數據一致性。
- 數據計算與加工:基于分布式計算框架(如Spark、Flink)進行數據聚合、關聯分析和特征工程,生成可供業務直接使用的數據模型。
- 數據質量監控:建立數據質量指標和告警機制,實時監測數據處理過程中的異常,保障數據的準確性與完整性。
三、構建通用數據處理架構的步驟
- 需求分析:明確業務場景與數據需求,例如實時報表、用戶畫像或預測分析。
- 技術選型:選擇適合的存儲(如HDFS、對象存儲)和計算引擎(如Hadoop、Spark),并考慮云原生或混合部署方案。
- 流水線設計:構建可配置的數據處理流水線,支持批處理和流處理,實現低延遲與高吞吐。
- 服務化與API化:將數據處理能力封裝為微服務或API,方便業務系統調用,提升數據復用性。
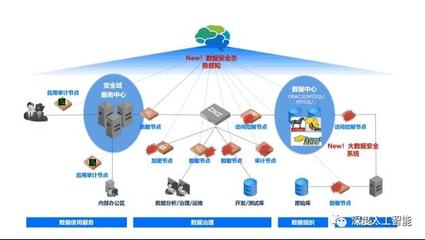
- 安全與治理:集成數據加密、權限控制和審計功能,遵循數據隱私法規(如GDPR)。
四、案例與最佳實踐
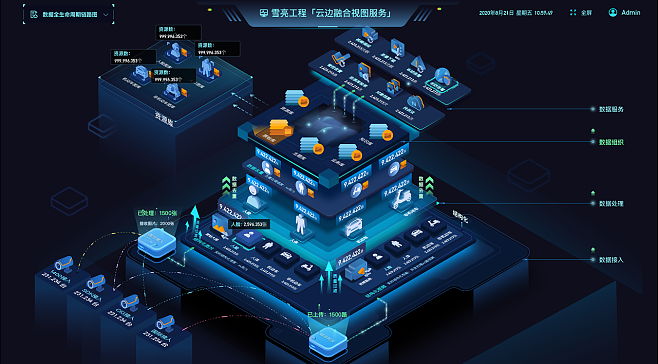
以某電商企業為例,其數據中臺通過數據處理服務整合了訂單、用戶和行為數據,實現了實時推薦和庫存預測。關鍵經驗包括:采用分層數據處理(原始層、明細層、匯總層),使用Kafka進行流數據攝取,并通過數據血緣工具追蹤數據流向。
五、未來展望
隨著AI和云技術的發展,數據處理服務將更智能化,例如通過自動優化計算資源、智能數據發現來降低運維成本。企業應持續迭代架構,以適應數據量的爆發式增長和業務多樣化需求。
一個通用的數據中臺架構依賴于強大的數據處理服務。通過模塊化設計、技術融合和治理保障,企業能夠釋放數據價值,加速數字化轉型。