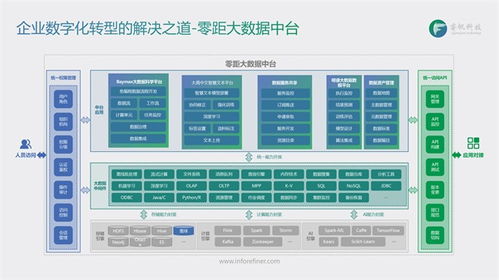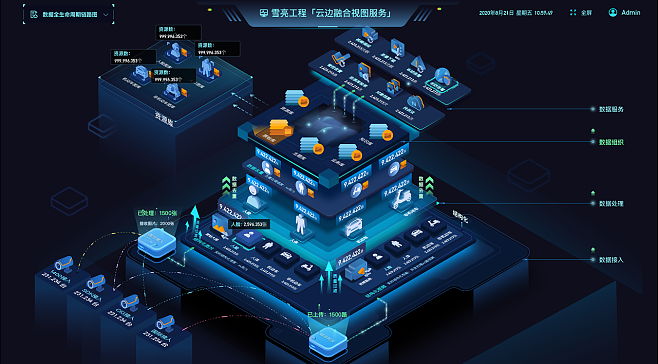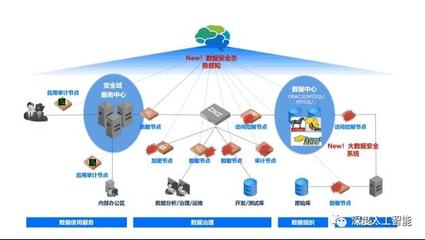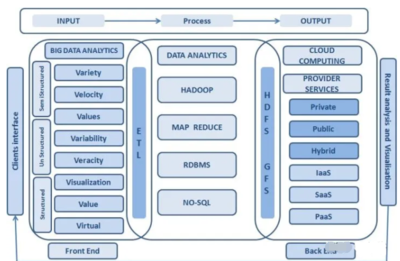
隨著云計算的普及,云原生開發已成為現代軟件構建的主流方式。它強調利用云平臺的彈性、可擴展性和自動化能力,幫助團隊高效交付應用。本指南將全面介紹云原生開發的核心概念,從容器到微服務,并深入探討數據處理服務的關鍵角色,為開發者提供實踐指導。
一、容器化:云原生開發的基石
容器是云原生架構的基礎,它通過輕量級虛擬化技術將應用及其依賴打包成獨立單元,確保環境一致性。Docker 是最流行的容器化工具,允許開發者在本地構建、測試鏡像,然后部署到任何支持容器的平臺。Kubernetes 作為容器編排系統,自動化管理容器的部署、擴縮容和故障恢復,是云原生生態的核心組件。通過容器化,團隊可以快速迭代應用,減少環境沖突,提升開發效率。
二、微服務架構:解耦復雜系統的關鍵
微服務將單體應用拆分為多個小型、獨立的服務,每個服務負責特定功能,并通過 API 進行通信。這種架構提高了系統的可維護性和可擴展性。在云原生環境中,微服務與容器天然契合:每個微服務可以封裝在一個容器中,由 Kubernetes 統一編排。開發者可以使用服務網格(如 Istio)管理服務間的通信、負載均衡和安全策略。微服務的引入促進了團隊協作,但也帶來了分布式系統的挑戰,如數據一致性和監控復雜性。
三、數據處理服務:云原生的數據驅動引擎
在云原生應用中,數據處理服務是不可或缺的部分,它支持實時流處理、批處理和數據分析。常見的數據處理工具包括 Apache Kafka 用于消息隊列,Apache Spark 用于大數據處理,以及云原生數據庫如 Amazon DynamoDB 或 Google Bigtable。這些服務與容器和微服務集成,提供高可用性和彈性伸縮能力。例如,在微服務架構中,事件驅動模式結合 Kafka 可以實現異步數據處理,提升系統響應速度。使用云原生數據湖(如 AWS S3)可以存儲海量數據,并通過服務如 Apache Flink 進行實時分析。
四、全棧實踐:構建端到端云原生應用
要構建完整的云原生應用,開發者需要整合容器、微服務和數據處理服務。實踐步驟包括:使用 Docker 容器化應用組件;利用 Kubernetes 部署微服務集群,并配置服務網格來優化通信;集成數據處理服務,如通過 Kafka 處理事件流,或使用云數據庫存儲用戶數據。監控和日志工具(如 Prometheus 和 Grafana)是必不可少的,它們幫助跟蹤應用性能和數據處理指標。通過 DevOps 和 CI/CD 流水線,團隊可以自動化測試和部署,確保快速交付。
五、挑戰與未來展望
盡管云原生開發帶來諸多優勢,但也面臨挑戰,如安全性、成本管理和技能要求。未來,隨著邊緣計算和 AI 的融合,云原生數據處理服務將更智能化,支持更多實時場景。開發者應持續學習新技術,例如服務網格的演進和云原生數據庫的創新,以適應不斷變化的行業需求。
云原生開發從容器到微服務,再到數據處理服務,形成了一個完整的生態系統。通過掌握這些核心要素,團隊可以構建高效、可靠的應用,推動數字化轉型。本指南旨在為初學者和進階開發者提供實用參考,助力在云原生旅程中取得成功。